Vector registers, SIMD, SWAR,Vector Chaining. Any Difference?
osd600

SIMD, single instruction multiple data is a very broad term. It is a concept. SIMD coud be implemented in parallel, or sequential; On one thread, or on multiple SIMT(single instruction multiple thread); On the GPU or on the CPU.
Is there some kind of magical vector register, that simultaneously can add vector 'a' to vector 'b', and store result in vector 'c'?
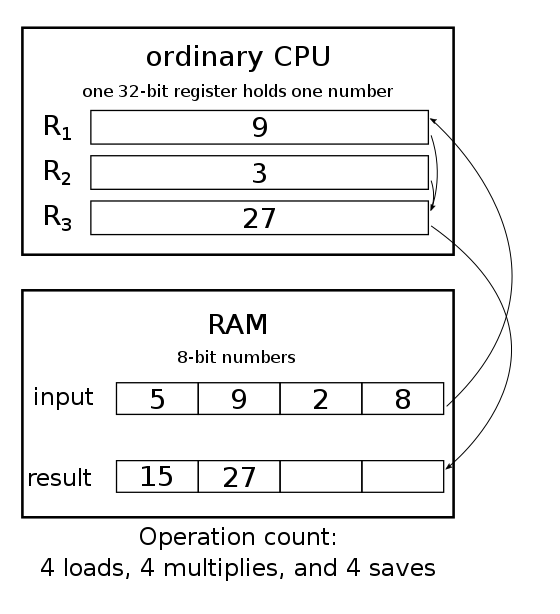
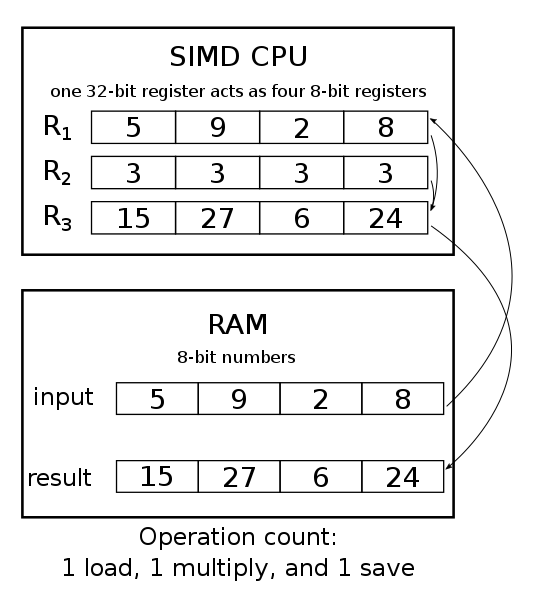
setvli $10 # Set vector length VL=10
vload v1, a # 10 loads from a
vload v2, b # 10 loads from b
vadd v3, v1, v2 # 10 adds
vstore v3, c # 10 stores into c
ret
Compared to regular implementation with a loop
; Hypothetical RISC machine
; add 10 numbers in a to 10 numbers in b, storing results in c
; assume a, b, and c are memory locations in their respective registers
move $10, count ; count := 10
loop:
load r1, a
load r2, b
add r3, r1, r2 ; r3 := r1 + r2
store r3, c
add a, a, $4 ; move on
add b, b, $4
add c, c, $4
dec count ; decrement
jnez count, loop ; loop back if count is not yet 0
ret
There are SIMD instructions in most of the architectures. x64, Aarch and so on. Does it mean in code snippet one, there is no iteration done and everything is added right away in parallel? Or is iteration is done in hardware, on transistor level.
Let's investigate .
Predicated SIMD
- it uses masking 2.associative Processor - These receive the one (same) instruction but in each parallel processing unit an independent decision is made, based on data local to the unit, as to whether to perform the execution or whether to skip it.
- allows to use variable length vectors, because it has prediction capabilities, to decide if it needs to continue processing data, or ready to stop.
- predicate masks allow parallel if/then/else constructs without branches
Packed SIMD
- Also known as SWAR, simd within a register
- ARM NEON was inspired by this
- form of a group of registers and instructions
- instructions explicitly intended to perform parallel operations across data that is stored in the independent subwords or fields of a register
Pure Vectors
- characterized by pipelined functional units that accept a sequential stream of array or vector elements
- I think it is related to vector chaining
The way I process information above
Predicated: parallel execution, more like multithreading. Does not happen at the same physical place. Both data and instructions in different place, but parallel.
Packed: Not sure, but this one looks more like everything is happening in one place, and with true parallelism. Perhaps like on the picture above, where one 32bit register acts like four 8bit registers.
Pure Vectors: calculations happen in one place, but pipelined (in order, one by one). So here like hardware accelerated 'for' loop for future reference
